How Atri AI Chat Works
System Architecture
Atri AI Chat leverages a comprehensive RAG (Retrieval-Augmented Generation) pipeline that processes your knowledge sources into intelligent conversational experiences. The system combines vector embeddings, semantic retrieval, and proprietary LLM workflows to ensure every response is both accurate and contextually relevant. This sophisticated architecture represents a significant advancement in conversational AI, delivering both the accuracy users need and the natural interaction they expect from modern AI assistants.
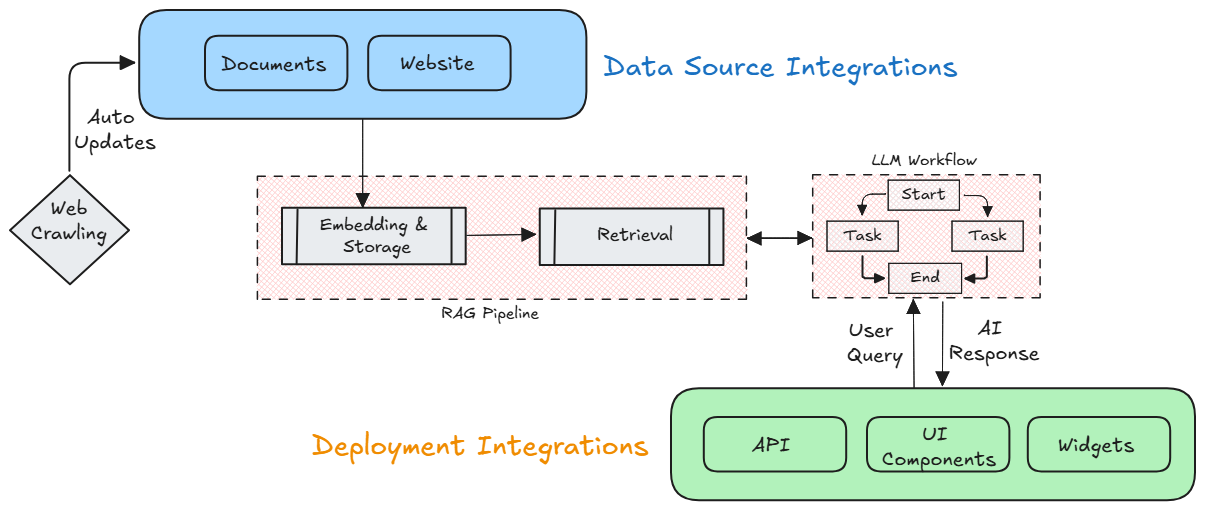
System architecture showing data source integrations, RAG pipeline, LLM workflow, and deployment integrations
The Conversational Process
The conversational process unfolds through four distinct phases, each designed to maximize both accuracy and naturalness. Understanding these phases helps illustrate how Atri AI Chat delivers accurate and intelligent responses.
Knowledge Source Processing
The foundation of intelligent conversation begins with comprehensive knowledge processing. Your documents and data sources are transformed into searchable vector embeddings that capture semantic meaning and context. This process goes beyond simple text storage, creating a rich understanding of your content that enables the AI to engage with nuanced concepts and relationships.
During this phase, the system performs several critical operations:
- Content ingestion from multiple sources including PDFs, documents, websites, and databases
- Text extraction and preprocessing to optimize content for embedding generation
- Vector embedding creation using state-of-the-art language models
- Semantic indexing that preserves context and relationships between information
Query Understanding & Context Retrieval
When users pose questions, the system first understands the intent of the query. Information request queries trigger intelligent context retrieval that identifies the most relevant information from your knowledge base, ensuring that responses draw from the most pertinent sources only.
The query understanding process encompasses:
- Natural language processing to understand user intent and context
- Semantic search across vector embeddings to find relevant content
- Context ranking and selection based on relevance and coherence
- Multi-source information synthesis for comprehensive context building
Response Generation
The response generation phase represents the culmination of the RAG pipeline, where retrieved context meets language models. Our proprietary LLM workflows generate contextually accurate responses with proper source attribution and natural conversational flow, ensuring that every interaction feels both informative and genuinely conversational.
Response generation is optimized through:
- Context engineering designed to pass the right context to LLMs
- Response grounding techniques to minimize hallucinations
- Automatic source citation and attribution for transparency
- Conversation memory integration for context continuity
Memory & Personalization
The final phase focuses on learning and adaptation, ensuring that each conversation contributes to an increasingly personalized experience. Each interaction contributes to building user context and improving future responses through persistent memory systems, creating AI assistants that truly understand and adapt to individual user needs.
Memory and personalization systems include:
- Conversation history analysis and pattern recognition
- User preference learning from interaction patterns
- Context accumulation for increasingly personalized responses
- Adaptive behavior modification based on user feedback
Technical Implementation
The technical implementation of Atri AI Chat represents an orchestration of cutting-edge AI technologies and proven conversational systems.
Vector Embeddings & Semantic Search
Advanced embedding models convert your content into high-dimensional vectors that capture semantic meaning, enabling the system to understand context, relationships, and nuanced information connections across your knowledge base. These embeddings form the foundation of the AI's ability to engage with complex topics and maintain contextual awareness throughout conversations.
RAG Pipeline Optimization
The Retrieval-Augmented Generation pipeline combines efficient retrieval mechanisms with sophisticated generation techniques, ensuring responses are both factually accurate and contextually appropriate. This approach leverages the strengths of both information retrieval and language generation, creating responses that are grounded in your specific content while maintaining natural conversational flow.
LLM Workflow Management
Complex workflow orchestration manages the interaction between retrieval systems and language models, incorporating prompt engineering, context management, and response validation for optimal output quality. This sophisticated management ensures that every component of the system works in harmony to deliver consistent, high-quality conversational experiences.
Persistent Memory Systems
Long-term memory capabilities track conversation history, user preferences, and interaction patterns, enabling personalized experiences that improve over time without compromising privacy or security. These systems ensure that your AI assistant becomes more helpful and relevant with each interaction, building genuine understanding of user needs and preferences.
Grounding & Attribution
Prompt engineering techniques ensure all responses remain anchored to source materials while providing clear attribution, building user trust through transparent and verifiable information sourcing. This grounding prevents hallucinations and ensures that users can always trace the origins of the information they receive.
Auto-Synchronization
Intelligent monitoring systems track changes in your knowledge sources, automatically updating vector embeddings and maintaining currency of information without manual intervention. This ensures that your conversational AI evolves alongside your content, maintaining accuracy and relevance as your knowledge base grows and changes.
Conversation Workflow
The complete journey from user query to intelligent response involves multiple steps working in harmony:
User submits natural language query
Query processing and intent analysis
Semantic search across knowledge base
Context retrieval and relevance scoring
LLM processing with retrieved context
Response generation with source attribution
Memory update and personalization learning
Delivery of accurate, personalized response